CosyVoice 3 - голосовой ИИ от Alibaba на миллион часов речи

TL;DR: Alibaba представили CosyVoice 3 - модель синтеза речи нового поколения. Обучена на миллионе часов аудио, понимает 9 языков и 18 китайских диалектов. Умеет клонировать голос, передавать эмоции и смешивать языки в одной фразе.
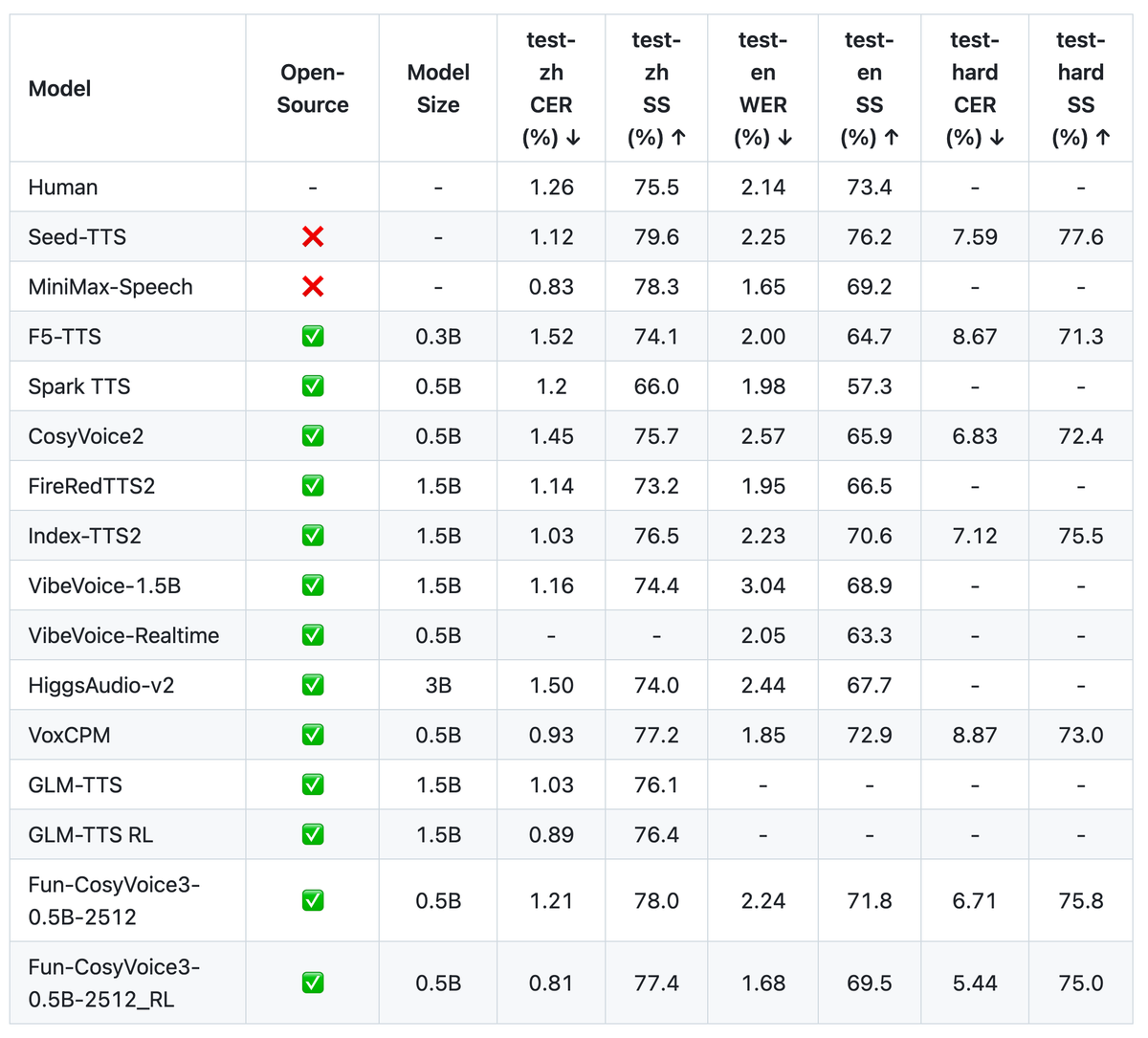
Привет! Команда FunAudioLLM из Alibaba выкатила третью версию своей модели синтеза речи CosyVoice. И тут есть на что посмотреть.
Что нового
Главное - масштаб. Датасет вырос с 10 тысяч часов до миллиона. Это примерно 114 лет непрерывной речи. Параметров тоже прибавилось - с 500 миллионов до 1.5 миллиарда.
Что умеет:
- Zero-shot клонирование - даёшь образец голоса, получаешь синтез этим голосом
- 9 языков - английский, китайский, японский, корейский, немецкий, испанский, французский, итальянский, русский
- 18 китайских диалектов - кантонский, сычуаньский, шанхайский и другие
- Эмоции - радость, грусть, страх, злость, удивление
- Смешивание языков - можно говорить на нескольких языках в одной фразе
Как это работает
Под капотом - комбинация LLM и технологии chunk-aware flow matching. Звучит сложно, но суть простая: модель понимает контекст и генерирует речь кусками, сохраняя естественность интонаций.
Интересная штука - новый токенизатор речи. Его обучали на нескольких задачах сразу: распознавание речи, определение эмоций, идентификация языка, анализ говорящего. Это помогает модели лучше передавать просодику - то, как мы выделяем слова и расставляем паузы.
Что это значит
Синтез речи становится всё ближе к человеческому. Миллион часов обучающих данных - это серьёзно. Думаю, скоро увидим эту модель в продуктах Alibaba, а может и в open-source.
Для тех, кто работает с голосовыми интерфейсами - стоит следить за развитием.
📚 Источники